
If you could have any superpower in the world, what would you choose?
That’s the question I ask people whenever I have to explain what data mining is and why it is so useful. The two most common answers to that question are flying and reading thoughts. It is quite clear why human beings are so fascinated by flying. Few things would feel as amazing as soaring through the air, but why is reading minds so intriguing?
It is not that hard to figure out an answer to that question. Reading thoughts would give us an insight into the inner world of a person. Stripping away the facade and socially desirable behavior allows us to understand and anticipate the actions of others. (Un)fortunately the great minds of this world have not figured out a way to give us these superpowers. However, social media does take us a step in that direction.
Social Media: the gateway to reading thoughts?
Social media allows us to post our uncensored thoughts, free from public inhibition from the privacy of our homes or any place in the world for that matter. Although the tide seems to be changing as people are starting to realize that their online actions can and at times do have real life consequences, the online world is still perceived by many as a separate entity from public life. It feels very private to write something on your phone or computer and send it out into the world. You don’t dwell on the fact that millions of people can read your most intimate thoughts, because those people are not standing in your room looking over your shoulder while you type something up.
And sure, most of the thoughts that people have are not that spectacular. Mundane tidbits about what we are going to eat next or whether we left the stove on occupy most of our thoughts. This is also evidenced by the amount of pictures of food that can be found on social media. However, people also use those channels to voice their unfiltered opinions about every topic under the sun. Including politics and legal matters. During the Arab revolution for example, social media was a safe haven for citizens to not only organize meetings but also (anonymously) voice their opinions.
Data Mining: collecting information
Recent years have caused a surge in the amount of data available on the Internet. This data can be used to extract information regarding a variety of topics. In order to distillate in-depth information from a set of data, a more powerful tool than the standard database query is required. These more powerful set of techniques are collectively called data mining. Data mining provides a way to find hidden information in a dataset. In particular descriptive data mining techniques, visualizations, can be used to help analyze large sets of information.
The question that was on my mind while thinking about data mining and social media is whether I could leverage these tools for the purpose of analyzing legal questions. Most of the research conducted at that time focused on privacy issues concerning data mining, but I wanted to see whether it was possible to utilize the information to analyze legal topics. In the end there were two specific questions that occupied my mind: can data mining from social media sources be considered an effective tool to measure rule of law in Hungary and if so, can the results of the data mining process provide improvements and a more detailed insight into the effects that legislation has on rule of law. Before we get to that part, it is important to take a look at the methodology that I set up.
Delineation: making choices
Rule of Law
The legal topic that I chose as the topic to data mine is rule of law. I had several reasons to pick rule of law. First, rule of law and access to justice are two topics that have always fascinated me throughout my studies. It is my personal belief that a lot of complex legal questions in essence always come back to the concept of rule of law. Second, rule of law is a concept on which many people unknowingly voice their opinion online. Third, I was inspired by the work of the World Justice Project (WJP).
The World Justice Project
The World Justice Project gathers and analyses information regarding rule of law through questionnaires in different countries. Through collecting data the WJP creates a Rule of Law Index that provides an insight to how rule of law affects ordinary citizens in various countries. However the work of the WJP has some drawbacks. The data sent in by the respondents on which the Rule of Law Index is based is limited compared to the data that can be found on social media. The answers of social media users are less guarded and politically correct as they provide their opinions anonymously in a casual setting. Furthermore, opinions of Twitter users are far more open-ended regarding subjects relating to rule of law then even open-ended questionnaires allow. Tweets can be phrased and formulated in any particular way. Rule of law could be mentioned in various settings that the questionnaire would not anticipate. Another aspect is that these questionnaires can take a long time to conduct and evaluate. In contrast to Twitter which could provide a real time measurement of rule of law. Finally, performing questionnaires by polling stations and experts in multiple countries is expensive. On the other hand, access to tweets is free and therefore cost savings can be made by using Twitter as a data source.
Twitter
Both Twitter and Facebook are frequently used social media channels in Hungary. I used Twitter as the source to data mine, for the simple reason that most Facebook accounts are restricted due to privacy settings.
Hungary
There are several reasons why I picked Hungary as my case study. The country that should serve as the population group cannot be a country with a very strong adherence to rule of law, as it is essential that some discrepancies can be analyzed through data mining. On the other hand, it can also not be a country with an extremely bad track record when it comes to rule of law, as there should be a quite an open and democratic society for people to voice their opinions freely.
To identify such as country I used the Rule of Law Index created by the World Justice Project. This index assesses a country’s adherence to rule of law. The World Justice Project scores countries between the numbers 0 and 1. Zero indicates the least adherence to rule of law, while 1 indicates the most adherence to rule of law. Hungary’s rule of law index is 0.58, which indicates and index number which is right in the middle of the spectrum. Therefore, adhering to the criteria laid down above, Hungary would make an interesting case study. Another important criterion was for the author to understand the tweets in the original language. I’m fluent in Hungarian, which made the choice clear cut.
Methodology
Legislation
Legislation related to rule of law is used as the main measurement point to derive overall conclusions from the data. The dates and occurrences on which the legislative act was enacted is used to highlight and measure the effects of rule of law in Hungary. For example, a possible effect would be a case where Twitter users would vent their possible fears and frustrations if a law would restrict certain aspects of rule of law. For delineation purposes only Hungarian legislation was taken into account.
The Definition of Rule of Law
The goal of my research was not to find a new definition for rule of law. Plenty of researchers and professionals have racked their brains on a single defining definition of rule of law. In stead I compiled existing definitions of rule of law that were defined by various institutions. These institutions represent various actors who have to deal with the concept of rule of law on a professional level.

Keywords
Keywords were then extracted from these definitions through a set of rules that were defined in my methodology and can be read in my paper. I might post the rules and the full list of keywords here once the paper is published. I ended up with 84 keywords that were used to data mine Twitter. The results of the keywords search on Twitter were raw HTML files.
Converting HTML files
These raw HTML files were then converted to JSON objects through a Java application. JSON objects contain all the relevant information of a tweet.
The relevant elements of the Tweet in this case were
- Username
- Text/Content of a Tweet
- Date
- Retweet
- Favorites
Transformation
The tweets were then put in an Excel database. A number of fields, besides the relevant elements above, were added. Most importantly the relevancy category. This criterion aims to denote its level of relevancy with regards to rule of law concepts.
Relevancy Extraction
The relevancy extraction is aimed to identify information about how relevant a tweet is. Although having found the tweets based on a keyword search raises, by definition, the likelihood of the tweet relating to the concept of rule of law, this fact alone not sufficient. Search algorithms are not perfect and due to the fact that the research is novel, no previous data exist with regards to how accurate such searches are for retrieving tweets with regards to rule of law. In addition, some tweets can be seen more relevant than others: if a tweet specifically identifies a law relating to rule of law in Hungary then that gives more information to work with for interpreting the results than a tweet just mentioning rule of law.
I set up four different categories that can be given to the relevancy (or the lack thereof) of a tweet. I will update my portfolio with this part of the methodology once my paper is published.
For every tweet examined there was one and exactly one relevancy category that it could fall into. While the above criteria could be straightforwardly applied in many cases, there were also a number of scenarios where the distinction was not so clear cut. Nonetheless the goal was to categorize such occurrences in a methodical way, to ensure that consistent categorization was performed for all tweets. A list of rules was set up that were used to decide in which relevancy category a particular tweet would fall. This list of rules can be found in the paper and I might make it available here once the paper is published.
Sampling
For a number of keywords where this set was deemed too large, a sampling method was employed to perform the analysis with the given resources in a way that would give statistically significant results. The calculations for sampling were based on the formula provided in the article of Krejcie & Morgan ‘Determining Sample Size for Research Activities’. The formula can be seen below. For determining the chance of a certain type of answer the results of the largest non sampled keyword set was used. In this case this formula applies to a population of tweets for a certain keyword. For this project the margin of error in samples used is 5% with a 90% confidence value. For generating the samples a random number generator was used, based on the number of tweets for the sampled keyword.
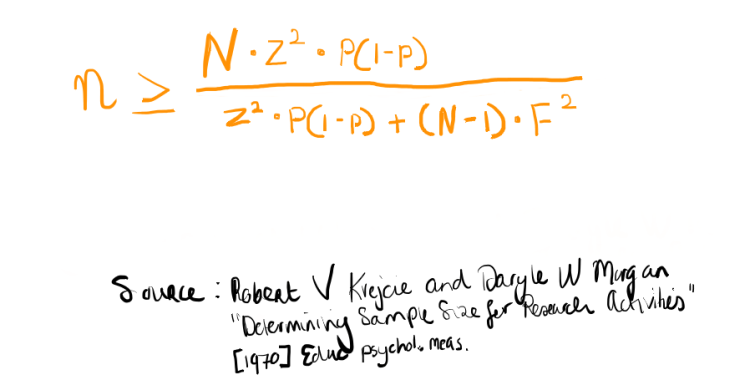
In this formula: n is the sample size, z is the standard deviation at a certain confidence percentage, N is the size of the population, P is the chance for a certain type of answer and F is the margin of error.
Visualization Extraction
Several descriptive visualization techniques were used to interpret the data sets. For every keyword a swarm chart (alternatively known as swarm plot) was created using the Seaborn visualization packages. This visualization allows for an overview of all the relevancy categories of the tweets mapped out over the time span of the tweets. The other visualization technique that was used is a word cloud created using the word_cloud Python package. This package was used to create a visualization based on the text of the tweets, in particular the frequencies of the words. In order to get the cleanest results a set of Hungarian stop words were used, in addition to a number of keywords in the technical domain to avoid frequently used technical phrases on the web, such “http” occurring in the visualization. In addition to these visualizations, the more commonly used pie chart was also used to denote the ratios of relevancy categories in a keyword directly. These visualizations, along with the raw categorized data sets, were used as a basis for interpretation.
In total this meant for each of those 84 keywords three visualizations were made per keyword: one swarm chart, one pie chart and one word cloud. This meant that the total number of visualizations was 252. I might put the visualizations in some form in my portfolio once my paper gets published, but until then I picked one keyword to show the readers in depth what the end result of my work was (please see below).
Interpretation
The interpretation step used the visualizations as well as the raw data sets for legal analysis.
Threats to Validity
As with all empirical research it is important to note possible threats to internal and external validity. There are several considerations that one has to keep in mind. Two of the main research considerations will be stated below.
Population considerations
The population of the Twitter users in Hungary are not the same as the general population as a whole. The age of the Twitter user group in Hungary and the category of people who are willing to comment on rule of law matters fall within the scope of a certain group. This issue is however mitigated due to the fact that Twitter is widely used in Hungary, and the platform is by its nature open, meaning that Twitter users would feel at home giving their opinions on the platform, likely even more so than in any other public setting.
Correlation versus causation
This research will use temporal aspects of the tweets occurrence in analysis in correlation with legislation. Causal links between legislation and tweets directly can be hard to draw due to the fact that events outside of the scope of the examined tweets can not be eliminated. However we can enhance the strength of the correlation by examining multiple keywords relating to rule of law. In addition, due to the large period of examined tweets, a good baseline could be established for rule of law related tweets without that particular event.
Alkotmány: the Constitution
I picked the keyword Alkotmány (the Constitution) to illustrate the results of my work. The keyword Alkotmány (the Constitution) had 129 results. Of these results, 68 tweets were categorized as relevant, 0 semi relevant, 25 not relevant, 32 were categorized as erroneous, and 4 were categorized as not clear. There were no semi relevant results as the keyword literally means the Constitution, and the Constitution is a law that is immediately placed in the relevant category as it fullfills the criteria set out in the methodology.
The swarm chart depicts frequent relevant results in the year 2011 and more specifically, an immense amassment of relevant results at the end of the first quarter of 2011. In 2012 there are almost no results on this topic with the exception of one. The year 2013 provides more frequent relevant results, while in 2014 and 2015 the frequency lowers again. The questions that now arise are: what happened in 2011 that caused a surge in relevant tweets and why did social media users react so fervently to this keyword? How come the frequency of relevant hits died down after 2011, and most importantly what were the changes regarding the Alkotmány keyword that shook up the public so much that a reaction on social media took place?
A first glance at the database regarding the relevant tweets of the first quarter of 2011 shows, that most of these relevant tweets are linked to events where the public discusses the new Constitution that will be introduced. The relevant events indicate that social media users expressed their worries regarding the effects that the new Constitution would have on various topics, such as: abortion, the introduction of the euro in Hungary, and fundamental rights in general. Furthermore, many tweets refer to demonstrations and protests taking place against the introduction of this new Constitution.  The annotated swarm chart seen above explicitly denotes where the important events in 2011 took place. In this swarm chart vertical lines were used to indicate events that took place with regards to the Constitution. The new Constitution was drafted on the 14th of March 2011 and adopted by the Fidesz/KDNP majority in the parliament on the 18th of April 2011. One can clearly see a concentration of relevant tweets regarding the keywords Constitution between that time period.
The annotated swarm chart seen above explicitly denotes where the important events in 2011 took place. In this swarm chart vertical lines were used to indicate events that took place with regards to the Constitution. The new Constitution was drafted on the 14th of March 2011 and adopted by the Fidesz/KDNP majority in the parliament on the 18th of April 2011. One can clearly see a concentration of relevant tweets regarding the keywords Constitution between that time period.
At this point, my research project continues by connecting the results of the data mining process with legal research. I will update this page with the analysis once my paper is published.
Conclusion
As mentioned earlier when I came up with the idea for this research project two questions popped up into my mind. One of them was whether it would be even possible to conduct data mining in order to extract knowledge from Twitter regarding the concept of rule of law. The research project has illustrated that it is indeed possible to data mine Twitter for keywords that can be linked to the concept of rule of law. However, there are some aspects that one has to keep in mind in conducting this type of research.
Although data mining was used to extract information from Twitter several aspects of the research process had to be conducted manually. For example, the data had to be analyzed and categorized in a separate database. This meant that every individual tweet that was data mined had to be manually analyzed and categorized. There are options to automate this part of the process, however, this falls outside the scope of a legal research project. Nevertheless, data mining keywords related to the concept of rule of law did succeed in measuring rule of law in Hungary. It is a cost efficient and relatively fast way to measure the public’s opinion on social media regarding the concept of rule of law in real-time.
The second question that I was wondering about when I set up this research project was whether the data mining process could provide insights to the effects of legislation that can be connected to the concept of rule of law. The results of the data mining process illustrated that there was a large influx of tweets in the first quarter of 2011. The surge of tweets in that time period indicates that the public was fervently reacting to the implementation of the new Constitution. Authorities could dismiss these tweets as mindless chatter on the Internet as they do not realize that valuable information, opinions and knowledge is shared by the public regarding the concept of rule of law on that platform. My legal analysis (which I will elaborate on in my paper) indicates that the fact that the Constitution was adopted in such a short period of time, created such a change in the concept of rule of law that it did not go unnoticed by the public. In this case tweets did not describe what a Twitter user had for breakfast that day, but rather tweets about the essence of a legal society were sent out into the world. Data that is extracted from Twitter can not just be dismissed as mindless chatter. It can also be an important tool for the public to react to various events – including events that relate to rule of law.
In my paper I use the analogy of an old Hungarian folktale. That well-known Hungarian folktale describes a father, either a king or a shopkeeper depending on the version of the story, who requests his three daughters to describe their love for him. The first two daughters compare the love they have for their father with that of the riches of the earth. The third and youngest daughter compares the love that she has for her father with that of salt. Offended, the father, exiles his daughter. On her travels she meets a young nobleman, they fall in love and marry. After hearing the story about his wife’s exile, the husband concocts a plan. He invites the father for a feast, but makes sure to not serve any salt in his dishes. During the meal, the father grows remorseful as he remembers how he reacted towards his daughter’s comment. To the father’s surprise, his daughter enters the room and they reconcile, as the father now understands the significance of comparing her love for him with salt. This seemingly unimportant social media tool can be compared to the salt as described in the Hungarian folktale. Twitter, like salt, is used by ordinary citizens. It would at first glance be considered as a superficial and unimportant platform, however this research project illustrates the importance of this tool. Both for citizens to voice their opinions regarding rule of law, but also for authorities to hear what the public has to say about legal matters that affect the daily lives of people.
Project Details This blog post is a heavily abridged version of my research project. It will be edited throughout the next few months with more examples and illustrations once the paper is published. Status: finished Publication: in progress
Copyrighted by Nóra Al Haider 2016
